Extraer y Limpiar
Introducción
Esta semana vamos a trabajar en conceptos básicos de modelado de datos para visualización, la fase exploratoria de los datos donde nos concentramos en formas de narrar a nosotros mismos. La semana pasada trabajaron en visualizaciones que buscaban contar una historia persuasiva, pero para llegar a esto debemos entender primero la naturaleza de los datos, conocer su estructura, observar patrones, y comenzar a hacernos preguntas que investigamos por medio de la manipulación y visualización rápida de los datos. Cuando estamos tratando de contar una historia persuasiva a un público general, las estrategias de visualización están dirigidas con precisión a aquello que hemos descubierto tras un proceso de análisis profundo de los datos. En cambio, la narración a nosotros mismos es más abierta a interpretaciones, expone múltiples posibilidades y poco a poco se va acotando hasta adquirir sentidos más singulares.
Para entender esto en términos de storytelling, piensen en todas las fotos que tienen guardadas en su celular. Estas esconden pistas de quiénes son ustedes: sus gustos, las personas o animales importantes en su vida, momentos que quieren recordar, etc. Esa colección de imágenes en sus múltiples facetas se parece a nuestros datos crudos, pues tiene muchas posibles historias por contar. Si quisieran reconocer esas historias, podrían comenzar a definir tipos de fotos y, en ese proceso, identificar algunos patrones que los definen a ustedes. Lo que estamos haciendo esta semana es esa tipificación: darle orden a una colección aparentemente desordenada. Estamos viendo todas las fotos pero bajo una estructura que nos revela a nosotros mismos las posibles historias. Singularizar algunas de ellas, escoger una en específico y articularla a un público general es lo que hacemos tras el proceso de modelado (tipificación, filtro y observación de toda la colección). En mi caso, de todas las fotos que tengo en el celular, puedo reconocer que algo importante en mi vida es mi gata Nila, quien llegó durante la pandemia y se las quiero presentar.

Ejercicio (opcional) ¿Tienen una foto en su celular que cuente una historia de su vida? Pueden compartirla en el canal de Intrographics en Slack y así nos conocemos un poco más entre todos. En este pequeño ejercicio harán mentalmente el proceso de modelado para tomar la decisión de la foto que quieren compartir.
Extraer
Ahora sí entremos en asunto. En este tutorial vamos a trabajar en la primera fase de modelado, que consiste en elegir nuestra fuente de datos (extraer) y explorarla para reconocer lo que tenemos en nuestras manos (limpiar).
En el momento de decidir nuestra fuente de datos para análisis y visualización tenemos dos tipos de fuentes disponibles:
- Datos estáticos: que están alojados en un archivo (.csv, .json, .xls, etc.) o en una base de datos. En este caso podemos ver la estructura y los datos completos.
- Datos dinámicos: que extraemos por medio de una aplicación (API, sensores o aplicaciones con cálculos matemáticos en tiempo real). En este tipo de fuente podemos reconocer la estructura inicial de los datos y una muestra de los que produce la aplicación, pero no conocemos todos los datos de manera anticipada como en el caso anterior.
En ambos, la primera aproximación a los datos la hacemos estudiando su estructura original y nuestro primer trabajo es definir el tipo de datos que le corresponde a cada variable. Observar la estructura es apenas una mirada parcial y opaca de las potencias que tiene la base de datos, pero es un paso importante para investigarlos.
Esta semana vamos a trabajar sobre una base de datos que nos muestra los sueldos de profesionales en diferentes disciplinas. La vamos a tratar de manera estática a pesar de ser una fuente que se actualiza recurrentemente (la próxima semana vamos a trabajar con datos dinámicos): https://docs.google.com/spreadsheets/d/1IPS5dBSGtwYVbjsfbaMCYIWnOuRmJcbequohNxCyGVw/edit?resourcekey#gid=1625408792
La primera vista del archivo nos revela la forma como están estructurados los datos y los tipos de variables disponibles:
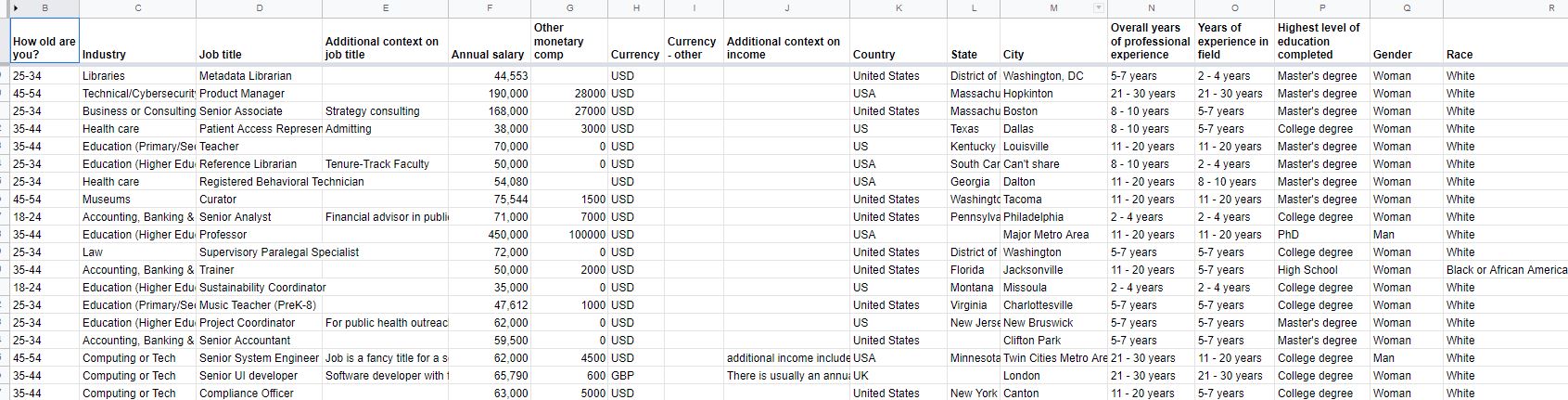
Figura 1
Estructura de datos “Ask A Manager Salary Survey 2021 (Responses)”
Fuente: https://docs.google.com/spreadsheets/d/1IPS5dBSGtwYVbjsfbaMCYIWnOuRmJcbequohNxCyGVw/edit?resourcekey#gid=1625408792
En un paneo rápido por el archivo podemos reconocer que hay dos tipos de variables: texto y números. Algunos campos de texto representan lugares geográficos y los números representan valores monetarios. (También hay variables con números como: “How old are you?”, “Overall years of profesional experience” y “Years of experience in the field”, pero en su estado crudo en la base de datos son variables de texto).
Incluso podemos reconocer que la población es principalmente estadounidense y con un esfuerzo adicional parece que son principalmente mujeres blancas. Seguro hay más cosas por descubrir, así que el primer paso es extraer esta base de datos para poderla trabajar.
Pueden descargar los datos en .csv desde “File -> Download -> Comma Separated Values (.csv)” y montarlos en su aplicación de visualización.
Si usan Looker Studio, pueden hacer una copia a su propia cuenta desde “File -> Make a Copy”. Luego van a Looker Studio, crean un reporte nuevo y en la opción “Connect Data” usan la opción “Google Sheets”
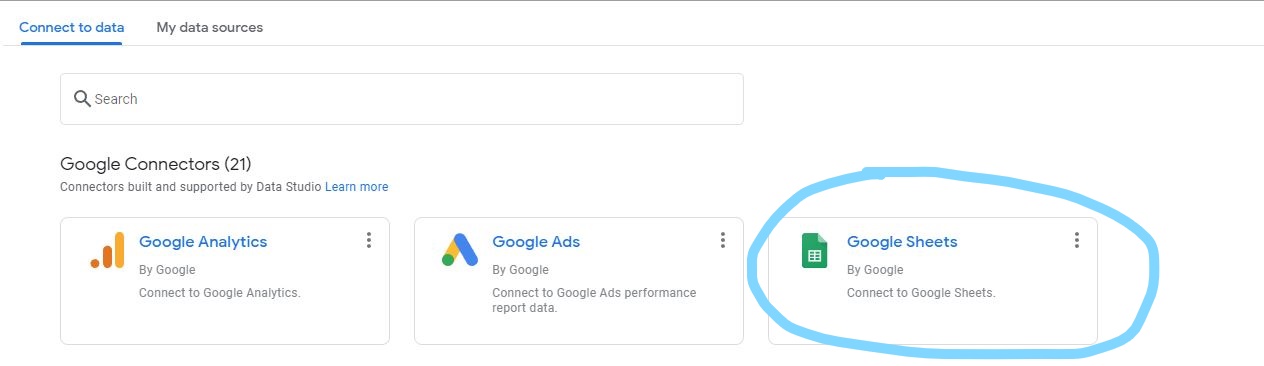
Figura 2
Conexión con Google Sheets paso 1
Aquí van a poder seleccionar la copia que acaban de hacer.
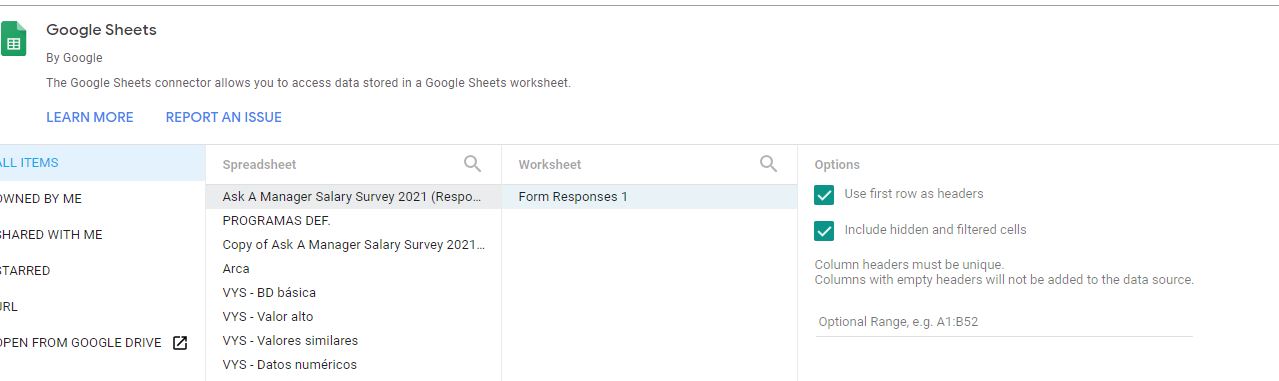
Figura 3
Conexión con Google Sheets paso 2
Al cargar los datos, pueden ver que Looker Studio reconoce inicialmente los tipos de variables que identificamos anteriormente: textos (ícono “ABC”) y números (ícono “123”). Se debe ver algo así:
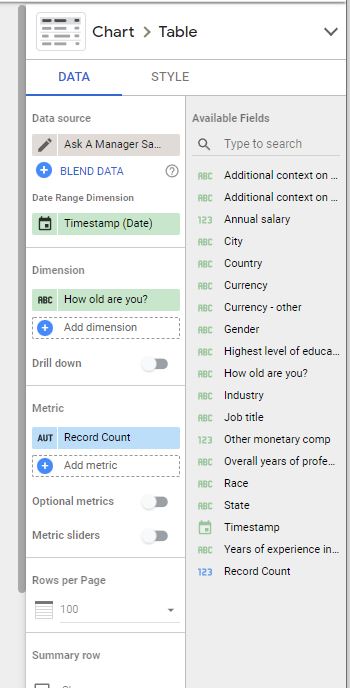
Figura 4
Variables iniciales
Ahora tenemos que especificar mejor estas variables definiendo el tipo de datos para comenzar el proceso de modelado. En Looker Studio van a “Resource -> Manage added data sources”
Figura 5
Fuentes de datos conectadas con el reporte
En la nueva pantalla seleccionan la opción “Edit”

Figura 6
Editar variables de la fuente de datos
En este espacio podemos editar y documentar las variables, idealmente el tipo de dato debe ser lo más específico posible. Por ejemplo, sabemos que hay campos con información geográfica que no son simplemente textos. Cambien “City” y “Country” a variables “Geo -> City” y “Geo -> Country” respectivamente. Van a ver que cambia el ícono de texto a uno con un globo como se ve acá:
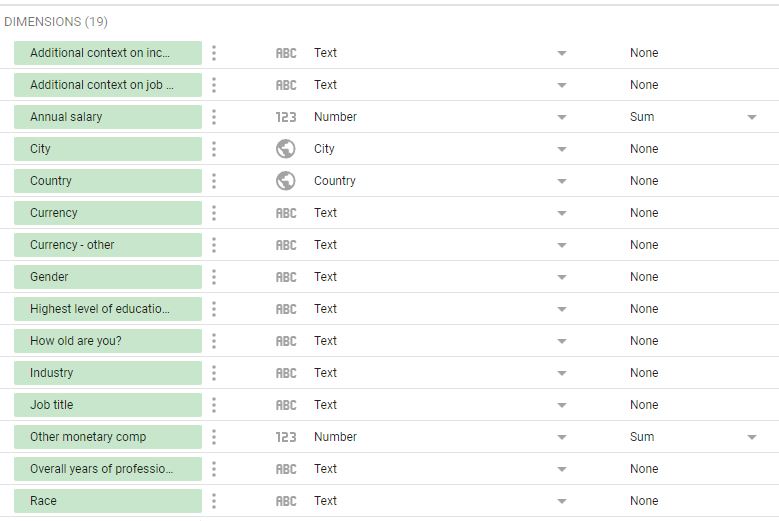
Figura 7
Definición de variables
En este punto tenemos los datos bien definidos para la base de datos inicial y podemos comenzar a visualizarlos.
Por último, una buena práctica a la hora de definir las variables es usar nombres cortos y descriptivos. Al mismo tiempo, agregar descripciones a medida que vamos modelando los datos nos ayuda a mantener bien documentado nuestro trabajo para facilitar nuevas iteraciones que hagamos sobre ellos y para poder entregarle nuestro trabajo a otra persona para que continúe desarrollando. A mí, por ejemplo, me gusta trabajar en español, así que cambié los nombres de las variables y agregué unas primeras descripciones. Así se ve mi primera fase de modelado en Looker Studio:
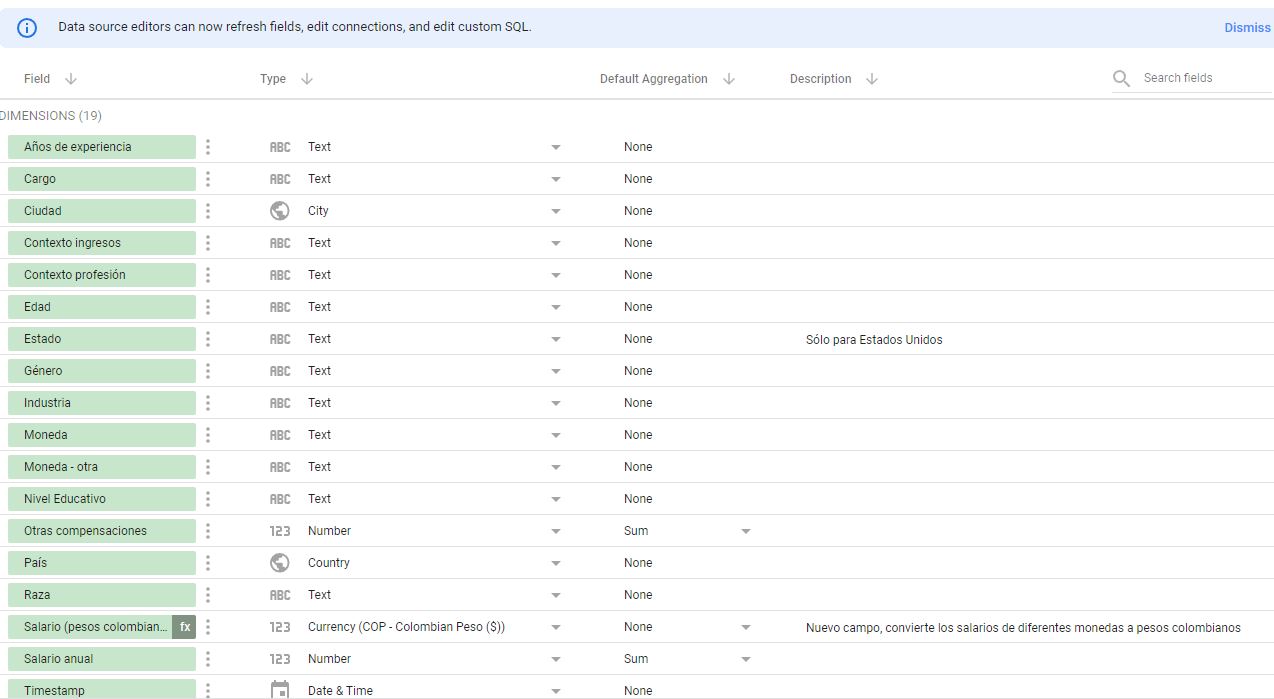
Figura 8
Nombres y descripciones en Looker Studio
Ustedes pueden mantener los nombres de las variables en inglés o crear sus propias traducciones. Cuando lo decidan, sean consistentes con todas las variables.
Limpiar
La base de datos con la que estamos trabajando esta semana es un ejemplo típico de la vida real, ofrece información interesante, pero puede estar llena de errores que debemos corregir.
Si revisamos el formulario desde el cual se capturan los datos, vamos a ver que hay varios campos de texto libre como “Country”. Esto produce resultados como el siguiente mapa:
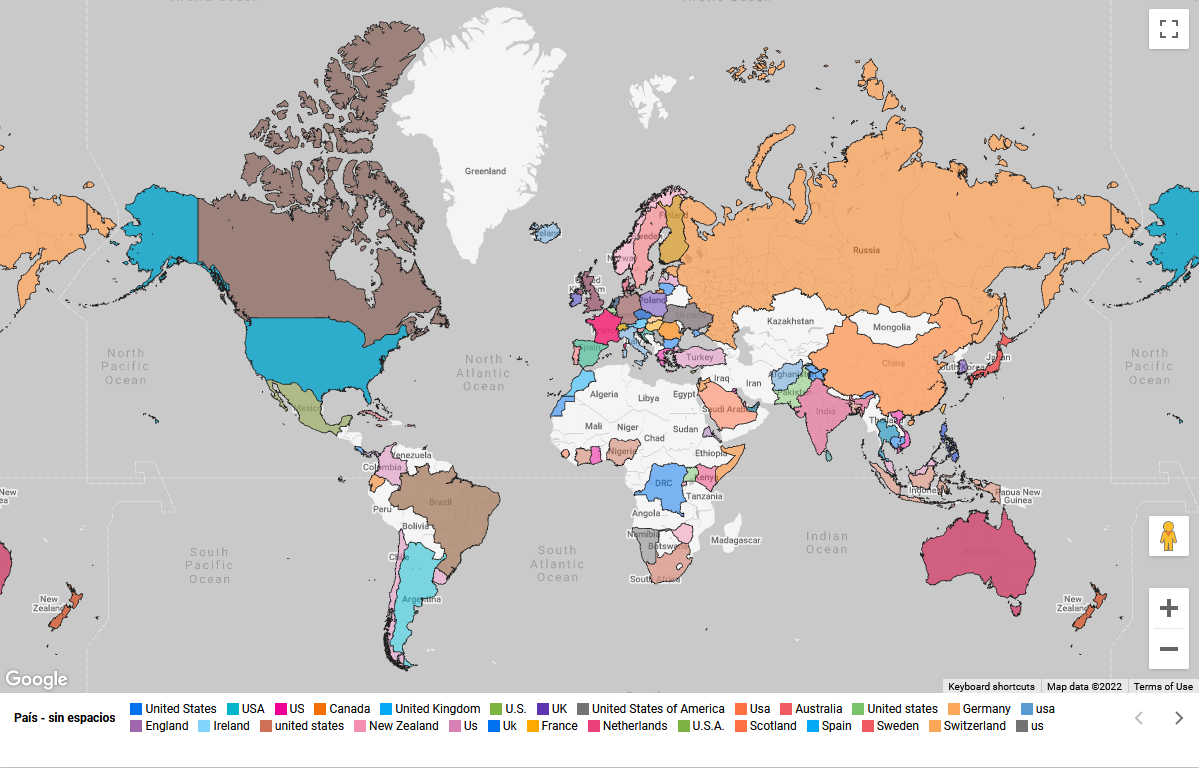
Figura 9
Nombres y descripciones en Looker Studio Para ver el reporte interactivo ir a: https://lookerstudio.google.com/reporting/369461f0-a5e7-4593-bf70-1d747e3ffc6c
¡Es un desastre! ¿Cuántas instancias diferentes hay de Estados Unidos? Hay muchas formas de escribir el nombre de un país y nuestra aplicación simplemente no las reconoce como uno solo.
Para limpiar los datos tienen dos opciones:
- Limpieza manual: Directamente en Excel o Google Sheets, pueden elegir una única forma de escribir el nombre de un país, buscar todas las otras y reemplazarlas por la que eligieron. Esto puede ser un proceso tedioso y poco productivo si queremos actualizar los datos en el futuro.
- Limpieza con “scripts”: En este caso debemos usar programación para automatizar la limpieza, implica siempre el reto de crear las fórmulas y probarlas detenidamente, pero una vez tenemos esto, actualizar los datos es automático y efectivo para un proyecto.
Para este ejercicio pueden elegir la opción que más les convenga, ya que estamos trabajando sobre datos estáticos que no van a cambiar en el futuro. Pero les voy a mostrar cómo crear un script para limpiar país en Looker Studio:
Pueden ver el siguiente video para el paso a paso, también está escrito después del video:
- Vamos de nuevo a “Resource -> Manage added data sources” seleccionamos “EDIT”.
- Cambiamos el nombre de la variable que está sucia, “País - Sucio”. Esto lo hacemos para poder identificar fácilmente la variable que vamos a reemplazar.
- Creamos un nuevo campo seleccionando “ADD FIELD”.
- Le damos un nombre a la variable en “Field name”. En mi caso va a ser “País” para saber que esta es la que va a quedar limpia.
- A continuación, la fórmula que parcialmente limpia el campo deben completarla ustedes:
CASE
WHEN TRIM(LOWER(País - Sucio)) IN ( "u.s.", "united states", "us", "america", "the united states", "the us", "u. s", "u. s.", "u.a.", "u.s", "u.s.", "u.s>", "u.sa", "ua", "u.s.a.", "usa", "u.s.a", "uxz", "united y", "united statss", "uniteed states", "usa (company is based in a us territory, i work remote)", "usa-- virgin islands", "usa, but for foreign gov't", "uniited states", "unite states", "united states", "united states of america", "unites states", "usa tomorrow", "unitef stated", "united states of american", "united stares", "united state", "united state of america", "united stated", "united stateds", "united states is america", "unitedstates" ) THEN "USA"
WHEN TRIM(LOWER(País - Sucio)) IN ( "united kingdom", "uk" ) THEN "UK"
ELSE TRIM(País - Sucio)
END
- Vuelven a entrar a “EDIT” y cambian el tipo de variable a “Geo -> Country”.
- (Opcional) Pueden esconder la variable que acabamos de reemplazar picando en los tres puntos grises al lado del nombre y seleccionan la opción “Hide”.
Veamos parte por parte lo que está haciendo la fórmula:
CASEabre la función yENDla cierra.- Entre
WHENeINseleccionamos la variable que queremos revisar que es “País- Sucio”. - La variable “País - Sucio” la estoy transformando antes de compararla usando las funciones
TRIM()yLOWER().TRIM()borra espacios al principio y al final del texto, un problema común en campos de texto manuales como este.LOWER()por otro lado, convierte todas las mayúsculas en minúsculas, para no tener que revisar tantas versiones del mismo texto. Por ejemplo, si no usamosLOWER(), el texto “United States” es diferente a “united states”, pero usando la funciónLOWER(), ambos son iguales y nos ahorramos mucho trabajo manual. - Teniendo en cuenta que transformamos el texto a minúsculas, podemos poner entre los paréntesis todas las versiones que significan lo mismo en minúsculas y no como están escritas en la base de datos.
- Luego de poner todas las versiones en las que está escrito el nombre de un país en la base de datos, concluimos la transformación escribiendo la versión que nosotros queremos usar después del
THEN. - Cuando terminen su fórmula, recuerden hacer clic en el botón “UPDATE” para guardar los cambios.
La fórmula que les estoy dejando como base es apenas una versión de cómo crear sus scripts. A medida que adquieran habilidades en programación, pueden crear fórmulas más cortas usando funciones como “REGEX” de manera inteligente y efectiva. Por ahora pueden completar la fórmula que les dejé acá para terminar de limpiar este campo.
Un guiño a las prácticas open-source
En este curso pueden compartir entre ustedes soluciones de programación para los ejercicios. Si alguien quiere compartir su solución al script con sus compañeros, siéntanse libres de hacerlo en el Slack. Aparte de ser permitido, ¡lo celebro!, pues este curso no se trata tanto de que aprendan a programar, sino de que aprendan a narrar. Entiendo que hay procesos técnicos que son necesarios para hacer las visualizaciones y se pueden ayudar entre todos para lograrlo. Espacios como GitHub o StackOverflow han demostrado la potencia de compartir y trabajar en comunidad, acá podemos hacer eco de estas nuevas formas pedagógicas.
Conclusiones
- El proceso de nombrar y tipificar las variables nos permite investigar los datos de manera inicial para comenzar a hacer preguntas y definir si necesitamos nuevas variables.
- Agregar descripciones a las variables es buena práctica profesional.
- Limpiar los datos es un proceso que puede ser tedioso y demorado, los scripts nos ayudan a agilizar este proceso.
- Limpiar los datos manualmente siempre es una posibilidad para datos estáticos. Los scripts, por otro lado, hacen que el proceso sea transferible a nuevos datos similares o permiten reproducir el modelado sobre nuevas versiones de la misma base de datos.