Escalas
Introducción
Una de las propiedades más importantes de nuestras visualizaciones serán los cambios de escala en las formas abstractas que utilizamos para describir las diferencias entre cada instancia de los datos. Visualmente decimos que X es mayor que Y mostrando cambios de escala entre dos formas similares entre sí.
Idealmente, en el momento de escoger el tipo de visualización que usamos para representar los datos, la escala de cada forma corresponde al valor absoluto. Así, hay una relación inmediata entre los datos y la traducción visual que estamos realizando. Veamos:
datos: [2, 8, 15, 25, 0, 11]
Figura 1
Ejemplos de escala
https://lookerstudio.google.com/reporting/a85fdd38-e11c-4c18-a23b-eac57fd3f16f
El acto de traducir datos a formas abstractas con cambios de escala lo vamos a llamar “mapear”, una tarea que típicamente delegamos a un proceso computacional. Es decir, una vez tenemos nuestros datos modelados y listos para ser visualizados, alimentamos el software de visualización con estos datos para que éste se encargue de mapear los valores cambiando las escalas y ubicándolas en el espacio visual por nosotros. Al mapear los datos, emerge entonces una gráfica que debería ayudarnos a narrar el fenómeno que tenemos en nuestras manos.
En todas las visualizaciones hay entonces dos tipos de procesos que deberíamos diferenciar claramente:
- Creativos: Los que nosotros decidimos.
- Computacionales: Los que delegamos al software para que construya a partir de nuestras decisiones creativas.
Ahora desagreguemos el proceso de hacer una visualización teniendo en cuenta estos dos procesos:
- Estructura de la fuente de datos (creativo)
- Los datos mismos (computacional o de la herramienta de captura)
- Modelado de datos (en la semana 3 vamos a profundizar en el proceso de modelado):
- Nueva estructura (se repite el punto 1, creativo)
- Transformación de estructura anterior a la nueva (computacional)
- Tipo de visualización con la que se van a mapear los datos (creativo)
- Mapeado o generación de visualización a partir de los datos (computacional)
- Narración alrededor del resultado de los pasos anteriores (creativo)
Como les dije inicialmente, la escala es una de las propiedades más importantes en visualización y al mismo tiempo se encuentra ubicada en el paso de mapear los datos (paso 5). Si es algo que delegamos a un proceso computacional quiere decir que para producir una visualización exitosa a nuestros propósitos debemos atender con cuidado el paso anterior que es la elección del tipo de visualización con el que vamos a mapear los datos.
Veamos algunos problemas típicos donde los cambios de escala se ven opacados por la decisión en la forma de visualizar.
Valores similares
En el siguiente ejemplo, los valores son muy similares entre sí, por ende, una visualización de barras o una torta se vuelven difíciles de leer a primera vista:
datos: [12.5, 12.1, 12.2, 11.5, 12.4]
Figura 2
Problemas con valores similares
https://lookerstudio.google.com/reporting/7e66bbb3-8843-4e26-8766-d4c019c89fa7
La torta en estos casos es una mala opción, pero con las barras podemos solucionar el problema cortando la base para poder diferenciar los valores con mayor resolución. Esto quiere decir que la base no comienza en 0 sino en un valor más alto. Veamos lo que sucede si hacemos el corte para que comience en 10:
Figura 3
Barras con valores similares y corte alto para mejorar resolución
https://lookerstudio.google.com/reporting/03f48dcf-2c02-4623-880b-5ab3d8b9c5d0
Para lograr esto en Looker Studio, deben ir a la sección "STYLE" y cambiar el valor de "Left Y-Axis" de su gráfica de barras:
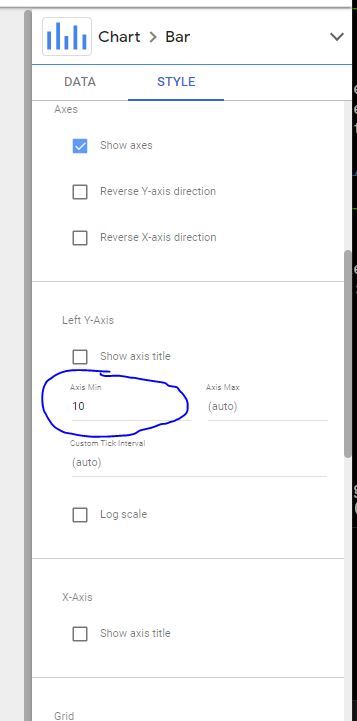
Figura 4
Cambiar corte del eje Y en Looker Studio
NOTA IMPORTANTE SOBRE CORTAR EL EJE: Cuando cortamos la base en una gráfica de barras, esta deja de ser preatencional, ya que el público debe revisar atentamente que la base ya no comienza en 0, que es lo que siempre asumimos inconscientemente. Adicionalmente, puede ser tentador cortar la base en todas las gráficas de barras para aumentar la resolución, pero si los valores no son tan similares, el corte puede producir una distorsión narrativa, ya que la diferencia entre las barras comienza a ser exagerada. Así que usen esta estrategia con cautela y en casos excepcionales.
Valores muy altos que reducen el espacio para comparar
Cuando tenemos un valor dramáticamente alto, el resultado automático de la gráfica puede hacer que el resto de valores se vuelvan imperceptibles. En la siguiente figura podemos ver este fenómeno en la gráfica de la izquierda. A la derecha usamos la misma estrategia de cortar el eje, pero en este caso en la parte superior. El máximo valor lo cambiamos a 1000 para hacer visibles las otras barras, pero no tan bajo para preservar la diferencia real entre los valores.
Figura 5
Barras con valor alto
https://lookerstudio.google.com/reporting/d3f2e1d6-270e-4211-976e-b4d1f4e6f0e4
Se ve bonito pero genera distorsión
Hay cierto tipo de gráficas que pueden producir resultados visualmente llamativos pero propensos a distorsionar la lectura, este es el caso de las barras radiales:
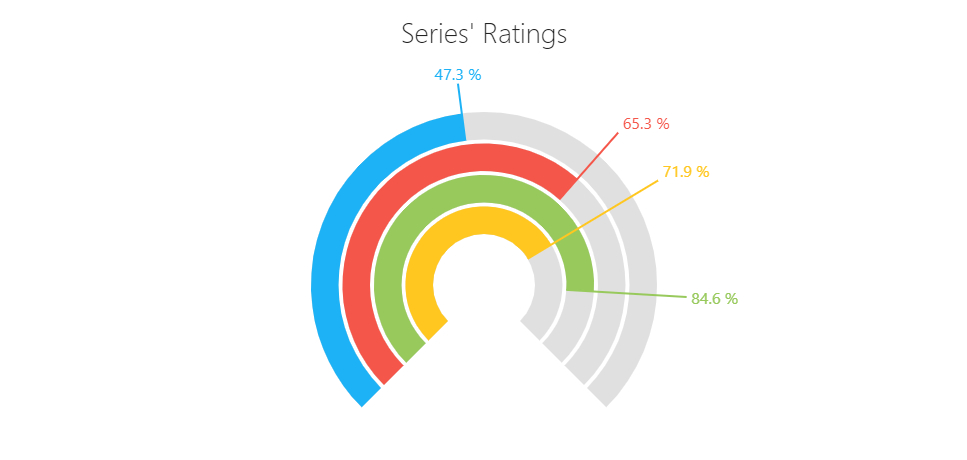
Figura 6
Ejemplo de barras radiales Fuente: https://js.devexpress.com/Demos/WidgetsGallery/Demo/Gauges/LabelsCustomization/jQuery/Light/
La distorsión se genera al desplazar las barras en diferentes radios, ya que esta transformación no es lineal como en las gráficas de barras tradicionales. En estos casos es preferible sacrificar lo estético y usar barras horizontales o verticales para no distorsionar los datos.
Resumen
- Las escalas de los elementos en una visualización tienden a ser un proceso computacional.
- Mapear los datos es el proceso de transformar una base de datos en su representación visual.
- La forma de visualizar puede opacar o hacer difícil su lectura a pesar de que las escalas corresponden fielmente a los datos.
- Negociamos entre decisiones propias y procesos computacionales para producir narraciones claras de los datos. Este curso se concentra sobre todo en cómo tomar las mejores decisiones para narrar con datos y no tanto en los procesos computacionales.
Ejercicio
La idea con este ejercicio es que prueben diferentes formas de visualización para describir características en la fuente de datos. Las características son aquellas posibles áreas de la fuente de datos que permiten contar algo sobre el fenómeno que contiene. En nuestro caso, ese fenómeno es la población del curso y algunas de sus características son: “Áreas de formación”, “Nivel de experiencia en visualización”, “Ubicación”, etc.
- Usar los datos de la población del curso como fuente de datos.
- Crear 2 visualizaciones que nos permitan comparar cantidades (barras, círculos, lollipops, etc.). No pueden usar el mismo tipo de visualización en ambas, si usan barras en una, la segunda no debe estar hecha con barras también. Prueben diferentes formas de visualizar para ver cuál describe mejor cada una de las siguientes características:
- Una visualización para describir las “Áreas de formación”.
- Una visualización para describir “Nivel de experiencia en visualización”.
- Crear una leyenda para cada visualización.
- Acompañar cada visualización con un texto corto (máximo 1 párrafo) que indique:
- Dónde están ustedes ubicados dentro de la población
- Comparado con sus compañeros que aspectos les gustaría mejorar dentro del curso y por qué.