Forma y Color

Introducción
Nuestro objetivo principal a la hora de crear visualizaciones de datos es poder comunicar claramente la información que contienen los datos. Lo primero que debemos tener en cuenta es que: Datos ≠ Información Los datos contienen información, pero somos nosotros quienes reconocemos esa información y se la transmitimos a nuestra audiencia.
Veamos un ejemplo con unos datos sencillos:
datos = [8, 2]
A simple vista podemos reconocer la diferencia entre estos dos valores y extraer información, podemos decir que:
- 8 es mayor que 2
- 2 es menor que 8
- o que hay una diferencia de 6 entre los dos valores.
Para extraer esa información debemos pasar por un proceso mental que requiere de nuestras habilidades conscientes. En teoría del lenguaje visual esto lo llamamos procesos “atencionales”. Tenemos que saber principios matemáticos básicos para extraer esta información de los datos.
Cuando tenemos una base de datos más compleja, se vuelve rápidamente complejo para nuestra audiencia la lectura.
Por ejemplo:
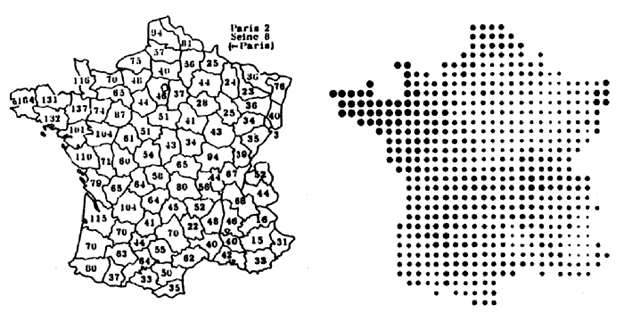
Figura 1
Jacques Bertin
Semiology of graphics: diagrams networks maps. (1983)
p.117 y 122
En el mapa de la izquierda, le pedimos a nuestra audiencia que explore detenidamente el mapa, que memorice los valores que va encontrando, los compare y haga pequeños cálculos matemáticos en su cabeza para determinar las diferencias entre las zonas del mapa. En otras palabras, son muchos procesos atencionales que rápidamente opacan la comprensión.
Pero en el mapa de la derecha, la información se hace inmediatamente evidente. La razón es que el mapa de la derecha se puede entender en un proceso que llamamos en teoría visual “preatención”. Los números desaparecen de la representación visual y son reemplazados por formas que indican el número, produciendo un mapa que nos pide comparar un patrón y no comparar números. En los procesos preatencionales, la mente puede memorizar una gran cantidad de valores y compararlos con facilidad.
Pero debemos reconocer que se hacen sacrificios, en el mapa de la derecha desaparecen:
- Los valores numéricos y por ende la posibilidad de precisar la cantidad. (Se puede solucionar desde la interacción como veremos más adelante).
- Los límites geográficos no están delimitados, el autor privilegia la información de los valores sobre la precisión de la zona geográfica al que corresponden. ¿se pierde información o se omite para facilitar la lectura de la información relevante?
Formas abstractas, información concreta
Pasar de los números a las formas no es un proceso automático necesariamente, ya que la posibilidad de leer una gráfica que apela a nuestra preatención requiere de un conocimiento intuitivo pero concreto.
Volvamos a nuestros datos sencillos:
datos = [8, 2]
Veamos algunas formas de visualizarlos para profundizar un poco en la teoría de preatención.
Cuando les digo que 8 es mayor que 2, visualmente lo puedo decir:
Figura 2
VYS - 2.1.1 Barras
https://lookerstudio.google.com/reporting/e376a6fd-fe27-495e-bcc4-bf40cd826d88/page/qg0gC
Figura 3
VYS - 2.1.2 Círculos
https://lookerstudio.google.com/reporting/57a116ef-f69e-4233-aaf0-6370cad2079a
Figura 4
VYS - 2.1.3 Torta
https://lookerstudio.google.com/reporting/4c8ed885-5be3-4d91-9929-ffd141d843fb
En estas gráficas, podemos ver intuitivamente la relación entre los dos valores a pesar de que las formas visuales son abstractas. Entre ellas comparten un principio fundamental: la forma crece a medida que incrementa el número. Pero una pequeña variación en las características de la forma puede comenzar a opacar su lectura. Veamos:
Errores que opacan la lectura
Figura 5
Gráfica de barras con elementos horizontales y variación de escala en el eje X.
Figura 6
Gráfica de burbujas con variación de escala en eje Y, creando óvalos difíciles de leer a primera vista.
En estos casos, los datos no están siendo distorsionados y "representan" fielmente los valores, pero la estrategia con la que variamos la forma hace que su lectura requiera de más atención. Pasamos de preatención a atención y eso es precisamente lo que queremos evitar en la primera lectura.
Otro error común en las visualizaciones es presentar todos los elementos con una forma sin variación, lo que hace necesario sobreponer otros elementos visuales que describan los valores que representan. Esto puede conducir rápidamente a algo como este mapa:

Figura 8
Cada punto representa un valor muy alto (1,000 personas) y el total de la población no necesariamente corresponde con la cantidad de puntos en el mapa. Mostrar 3,075 muertos con 3 pequeños puntos en el mapa conduce a una terrible distorsión del fenómeno representado.
Fuente: https://viz.wtf/image/625452155235647488
Resumen
- Los datos no son información.
- La información es aquello que nosotros reconocemos en los datos y lo hacemos visible a nuestra audiencia.
- El lenguaje visual es efectivo en la medida que su primera lectura haga uso de los procesos preatencionales.
- Las formas visuales, a pesar de ser abstractas en las visualizaciones, deben apelar a lo concreto.
- La manera de presentar la información involucra nuestra intención retórica.
Para profundizar
- Bertin, J. (1983). Semiology of graphics; diagrams networks maps: Un importante texto sobre el lenguaje de las gráficas. Los conceptos desarrollados por Bertin en su libro, los encontramos aplicados constantemente en software de visualización hoy en día.
- From Data to Viz. https://www.data-to-viz.com/: Un excelente recurso para conocer tipos de visualizaciones y sugerencias de casos para usarlos.
- WTF https://viz.wtf/: Una colección de visualizaciones mal hechas, algunas deliberadamente para distorsionar los datos, y otras por descuido de quienes las hacen. A primera vista parecen todas absurdas, pero los invito a que visiten el sitio (se actualiza permanentemente) y hagan el ejercicio de pensar en los conceptos que propone este curso en relación a los casos reales que aquí se presentan.
Ejercicio
Usando la base de datos que creamos en la primera semana, quiero que investiguen los datos para identificar una posible forma de narrarle a un público general una historia sobre la población del curso. Esta historia es algo que ustedes van a definir libres y de forma creativa luego de estudiar los datos.
- CSV con resultados de encuesta 1: Aquí.
Quiero que, de manera individual, describan visualmente a la población que compone este curso en un dashboard que nos muestre los diferentes grupos poblaciones. Pueden agrupar por profesión, habilidades o ubicación, y el objetivo es que escojan formas visuales que comparativamente describan las diferencias entre los miembros del curso. A lo largo de los siguientes tutoriales van a ir desarrollando partes del dashboard, pero pueden agregar otras visualizaciones adicionales que apoyen su historia.
Deben preguntarse:
- ¿Qué forma se relaciona mejor con el tipo de datos que eligen narrar?
- ¿Puede un público general reconocer inmediatamente las diferencias en la población?
- ¿Si cambio la forma, se compromete la comprensión de los datos?
El producto de esta visualización es un enlace que deben subir a la plataforma en: https://www.coursera.org/learn/visualizacin-y-storytelling/assignment-submission/aSR2W/ensamblaje. Este puede ser una imagen creada a mano, en Looker Studio, o si lo hacen en otro software de visualización que no genere enlace en la web, pueden tomar foto de la pantalla y subir ese archivo.